Table of Contents
Context Window Poisoning: The Hidden Trap in LLM Conversations

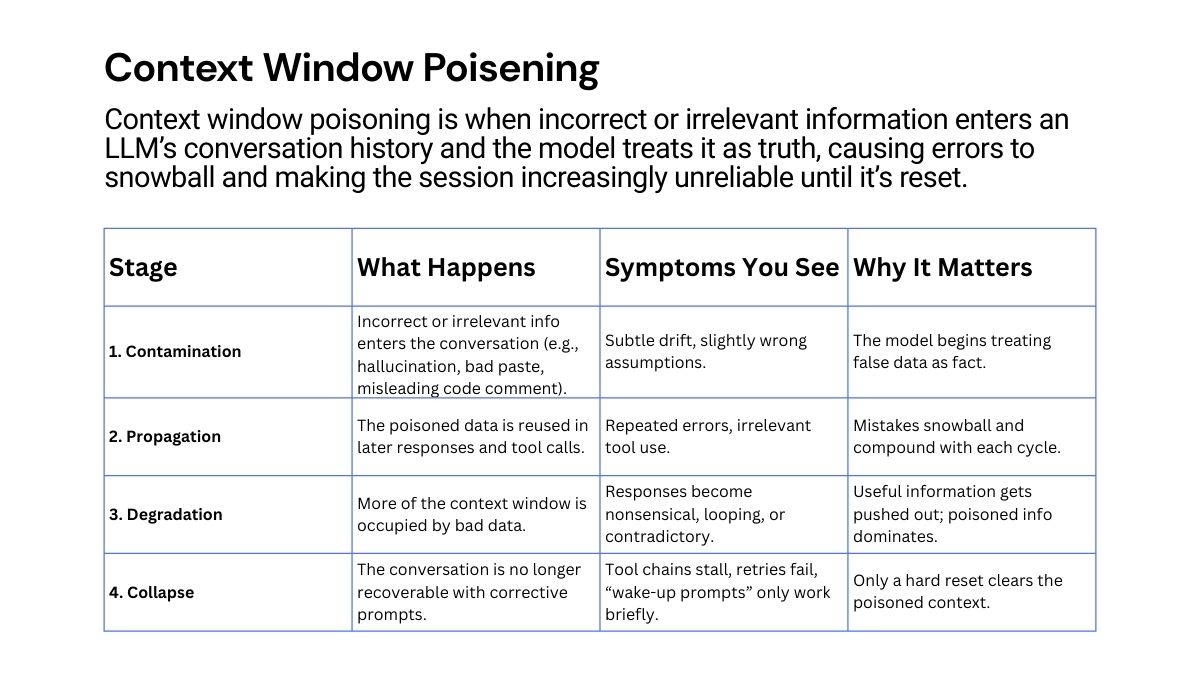
“Context window poisoning is when incorrect or irrelevant information enters an LLM’s conversation history and the model treats it as truth, causing errors to snowball and making the session increasingly unreliable until it’s reset.”
One of the biggest challenges when working with large language models (LLMs) is what I’d call context window poisoning. Once a mistake enters the active conversation, it tends to snowball.
The model doesn’t just make a single error — it often repeats that error, tries to “fix” it with quick patches, and ends up introducing even more problems. Instead of stepping back and addressing the root cause (for example, restructuring code properly), it layers shaky fixes on top of one another. Unless the poisoned data is removed, it becomes nearly impossible to steer the conversation back to a useful outcome.
What Is Context Window Poisoning?
At its core, context poisoning happens when inaccurate or irrelevant information contaminates the model’s working memory — its context window. Once that data is “in play,” the model treats it as truth. From there, it starts making faulty assumptions, issuing bad tool calls, and slowly drifting away from the intended task.
| Stage | What Happens | Symptoms You See | Why It Matters |
|---|---|---|---|
| 1. Contamination | Incorrect or irrelevant info enters the conversation (e.g., hallucination, bad paste, misleading code comment). | Subtle drift, slightly wrong assumptions. | The model begins treating false data as fact. |
| 2. Propagation | The poisoned data is reused in later responses and tool calls. | Repeated errors, irrelevant tool use. | Mistakes snowball and compound with each cycle. |
| 3. Degradation | More of the context window is occupied by bad data. | Responses become nonsensical, looping, or contradictory. | Useful information gets pushed out; poisoned info dominates. |
| 4. Collapse | The conversation is no longer recoverable with corrective prompts. | Tool chains stall, retries fail, “wake-up prompts” only work briefly. | Only a hard reset clears the poisoned context. |
Common Symptoms
You can often spot context poisoning by watching for:
- Degraded Output Quality — Responses become repetitive, irrelevant, or nonsensical.
- Tool Misalignment — Tool calls stop matching the user’s instructions.
- Orchestration Failures — Workflow chains stall, loop indefinitely, or fail to complete.
- Temporary Fixes Only — A clean instruction works briefly, then issues resurface.
- Tool Confusion — The model forgets how to use tools it previously understood.
Why It Happens
Several factors can trigger poisoning:
- Hallucinations — The model generates a false detail and then treats it as fact.
- Misleading Code Comments — Outdated or ambiguous notes in code misdirect the AI.
- Contaminated Input — Copy-pasted logs with rogue characters pollute the buffer.
- Context Window Overflow — As sessions grow, older useful details get pushed out while poisoned fragments remain influential.
Once bad information enters, it tends to persist. The model reevaluates and reuses this corrupted data in later cycles — like a flaw in a lens that distorts every view until the lens is replaced.
Why a “Wake-Up Prompt” Won’t Fix It
A common question is: “Can I just inject a corrective prompt to reset the model?”
Short answer: No.
Corrective prompts might temporarily mask the problem, but the corrupted information is still there in the context window. As soon as the conversation shifts beyond the narrow fix, the poisoning reappears.
Think of it like putting a warning label on a leaking pipe — the damage is still happening underneath.
Coping Strategies
Until LLMs have more advanced context management, users have developed workarounds:
- Hard Reset the Session — Starting fresh is the most reliable solution.
- Be Selective With Data — Only paste the essentials when sharing logs or text.
- Break Large Tasks Into Smaller Sessions — Prevents irrelevant details from lingering.
- Give Guardrails — Explicitly instruct the model not to retry failed approaches.
- Validate Tool Output — If a tool returns nonsense, delete it before the model integrates it into its reasoning.
- Maintain a Project Log — Keep a living record of goals, state, and todos outside the chat so you can reintroduce clean context when needed.
The Missing “Eject” Button
Many users have wished for an “eject” or “fork” button — the ability to restart a thread from a clean point in the conversation. Some tools experiment with this (Claude’s Edit button, Google’s AI Studio branching, LM Studio’s Fork, or Librechat’s message forking), but none offer a universal solution.
And even with forking, the risk remains: editing often resends the entire modified conversation back into the model, which can overflow the context window or reintroduce the very mistakes you’re trying to escape.
Where Feluda Fits In
This is exactly where Feluda offers a smarter approach. Instead of relying solely on fragile chat history, Feluda introduces Genes — modular, task-focused skill sets that compartmentalize workflows. Explore them in the Genes Library.
Examples include:
- The CVE Fetcher Gene for structured vulnerability intelligence.
- The Cyber RSS Reader Gene to track security updates separately from your main context.
- Prompt Packs that provide reusable scaffolds, reducing repetitive mistakes.
On top of this, Feluda includes journaling — the AI can document steps, record decisions, and log progress externally. Instead of bloating the conversation window, those notes act as a persistent project scratchpad.
This allows you to:
- Roll back to a clean state without losing continuity.
- Preserve structured memory across sessions.
- Prevent context poisoning from spiraling out of control.
The Bottom Line
Context window poisoning reveals the fragility of long-form interactions in today’s LLMs. The more retries and clarifications stack up, the more unreliable the model becomes.
Agentic frameworks are beginning to address this with structured memory and decomposition. But Feluda goes further: by combining Genes with journaling, it gives you a built-in safety net against poisoning.
👉 If your LLM session goes off the rails, don’t waste time patching it. Instead, make Feluda work for you — modularize your tasks, externalize the messy steps, and keep your context clean.
Because once the context is poisoned, prevention is far easier than recovery.